大数据查询语句总结 SQL summary in one (updating)
Author: Zizhun Guo
作者:
写于:
Why long query?
It depends on the complexity of the business; a simple query demand may involve multiple feature tables, each of which contains columns necessary to inquire, while the number of columns for each table is few. The way to implement a long query is diverse. However, we may intend to make our query as simple as possible. The simple SQL query refers to the query with the least select statement and subqueries. The subquery can visually deduct the line number of the code block but may lead to other problems, i.e., row explosion, etc.
How to optimize it?
A feasible way is to make the long SQL query a collection of blocks of code, which are much easier to control and to check for mistakes. Building your query a step at a time is a best practice for SQL development. This will enable you to find logical errors faster and be more confident of your results.
1.1 Flexible Left Join
A left join is frequently used in the long SQL query since it plays a filter role. The example down the side adds the new columns tag that indicates if the player is AI or not.
with v1 (
SELECT
t1.*
,IF(t2.uid is not null, 1, 0) AS player0_is_AI
,IF(t3.uid is not null, 1, 0) AS player1_is_AI
FROM
dwd_basic t1
LEFT JOIN
dwd.dwd_user_AI t2
ON
t1.player0_id = t2.uid
LEFT JOIN
dwd.dwd_user_AI t3
ON
t1.player1_id = t3.uid
)
select * from t where player0_is_AI = 1
1.2 Illustrated SQL join
Create the testing tables:
CREATE TABLE IF NOT EXISTS db.test_join_A
(
id INT
,name STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
;
CREATE TABLE IF NOT EXISTS db.test_join_B
(
id INT
,company STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
;
INSERT into TABLE db.test_join_a VALUES (1, 'Melisa');
INSERT into TABLE db.test_join_a VALUES (2, 'John');
INSERT into TABLE db.test_join_a VALUES (3, 'Kobe');
INSERT into TABLE db.test_join_a VALUES (4, 'Wanda');
INSERT into TABLE db.test_join_b VALUES (3, 'Apple');
INSERT into TABLE db.test_join_b VALUES (4, 'Microsoft');
INSERT into TABLE db.test_join_b VALUES (5, 'Shein');
INSERT into TABLE db.test_join_b VALUES (6, 'JD.com');
Print Left Join result:
select
t1.id
,t2.id
,t1.name
,t2.company
from
guozz.test_join_A t1
left join
guozz.test_join_B t2
on
t1.id = t2.id
;

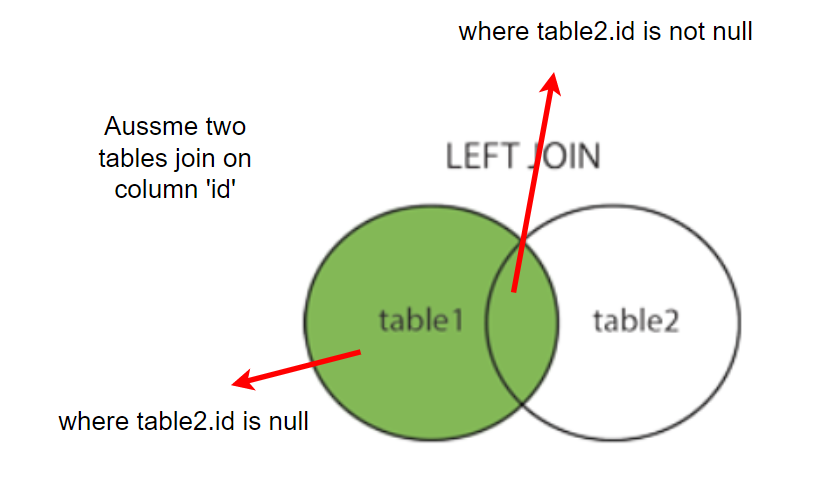
If t2.id is not null, it indicates the overlapping area.
select
t1.id
,t2.id
,t1.name
,t2.company
,if(t2.id is not null, 1, 0) as is_from_B
from
guozz.test_join_A t1
left join
guozz.test_join_B t2
on
t1.id = t2.id
;
If t2.id is not null, it indicates the non-overlapping area.

select
t1.id
,t2.id
,t1.name
,t2.company
,if(t2.id is null, 1, 0) as is_from_A
from
guozz.test_join_A t1
left join
guozz.test_join_B t2
on
t1.id = t2.id
;

1.3 Intermediate Table
An intermediate table is a table created on the database to store temporary data used to calculate the final result set.
%spark.pyspark
sql = f"""
with v= as (.......),
v2 as (.......),
v3 as (.......)
select * from v3 where.....
"""
df = hive_contxt.sql(sql)
From the above example, anything between the query could go wrong. If shit hits the fan, not only the time wasted, but there could have more mistakes go born. A feasible way is to write the intermediate result into the HDFS as a hive table. For tables frequently used as the source features of all other types of specific business queries, it is best to make them permanent tables.
The definition of CTE: The common table expression (CTE) is a powerful construct in SQL that helps simplify a query. CTEs work as virtual tables (with records and columns), created during the execution of a query, used by the query, and eliminated after query execution.
SQL Syntax Format
3.1 Benifit of Indentation
Indentation makes the block of codes more understandable by giving a visual cleanness which helps developers identify the position of elements and comprehend the logic.
SELECT
column1
,column2
FROM
table1
WHERE column3 IN
(
SELECT
TOP(1) column4
FROM
table2
INNER JOIN
table3
ON
table2.column1 = table3.column1
)
vs
SELECT column1, column2 FROM table1 WHERE column3 IN ( SELECT TOP(1) column4 FROM table2 INNER JOIN table3 ON table2.column1 = table3.column1)
3.2 Comma position in selection clause
Putting commas in front could visually help debug the codes. It also reduces making SQL parsing issues while writing the codes, making it easy to find where we miss placing the comma.
SELECT
a
,b
,c
, sum(case when d = 1 then 1 else 0 end) as dd
, row_number() over(partition by a, b order by c) as ee
, f + g + h as ii
FROM
t
vs
SELECT
a
b,
c,
sum(case when d = 1 then 1 else 0 end) as dd,
row_number() over(partition by a, b order by c) as ee,
f + g + h as ii,
FROM
t
;
3.3 Alias Usage
with v1 as (
select
a
,b
,c
from dwd.record_info
)
SELECT
t.a + t.b
FROM
v1 t
;
vs
with v1 as (
select
a
,b
,c
from dwd.record_info t
),
v2 as (
select
b + a as a
,a + 1 as b
from
v1 t
where
a + b > 10
)
SELECT
t.a + t.b
FROM
v2 t
;
Alias helps query works within the context, which means if you change the table name in the ‘from’ clasuse to another, it won’t bother you to re-edit all references in the selection clause.
3.4 Distinct helps prevent row explosion
select
t1.a
from
order_info t1
inner join
game_info t2
on
t1.uid = t2.uid
;
If both order_info and game_info tables have duplicate uids, joining them on the uid column would cause the row explosion. The distinct clause can solve it by eliminating the duplicates first.
select
t1.a
from
(select distinct uid from order_info) t1
inner join
(select distinct uid from game_info) t2
on
t1.uid = t2.uid
;
to be continued….
Copyright @ 2021 Zizhun Guo. All Rights Reserved.