Yolo背景和模型架构 YOLO Background & YOLO v4 tiny Archintecture
Author: Zizhun Guo
作者:
写于:
Background
Object detection is the main direction of computer vision and digital image processing. It has important practical significance to reduce the consumption of human capital through computer vision in many fields such as robot navigation, intelligent video surveillance, industrial detection, and aerospace. Therefore, object detection has become a research hotspot in theory and application. It is an important branch of image processing and computer vision and is also a core part of intelligent monitoring systems. At the same time, object detection is also a basic algorithm in the field of generic recognition. It plays a vital role in subsequent tasks such as face recognition, gait recognition, crowd counting, and instance segmentation. The detection method mainly introduces two target detection algorithm ideas based on deep learning, a one-stage object detection algorithm, and a two-stage target detection algorithm.

The task of object detection can be divided into two key subtasks: object classification and object localization. The object classification task is responsible for judging whether there are objects of the interest category in the input image or the selected image area (Proposals) and output the possibility of a series of scored labels indicating that the objects of the interest category appear in the input image or the selected image area (Proposals). The object localization task is responsible for determining the position and range of the object of interest in the input image or the selected image area (Proposals), the bounding box of the output object, or the center of the object, or the closed boundary of the object, etc., usually a square bounding box, namely Bounding Box is used to represent the location information of an object.
Existing Approaches
The current mainstream object detection algorithms are mainly based on deep learning models, which can be roughly divided into two categories: (1) One-Stage target detection algorithms: this type of detection algorithm does not require the Region Proposal stage, and can directly generate the category probability of the object and the position coordinate value, the more typical algorithms are YOLO, SSD and CornerNet; (2) Two-Stage target detection algorithm: this kind of detection algorithm divides the detection problem into two stages, the first stage generates the candidate region (Region Proposals), which contains the approximate location information of the object, and then classifies and refines the location of the candidate area in the second stage. Typical representatives of this type of algorithm are R-CNN, Fast R-CNN, Faster R-CNN, etc.
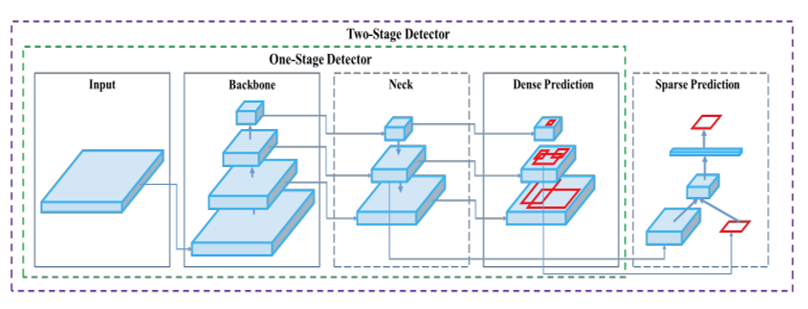
The One-Stage object detection algorithm can directly generate the category probability and position coordinate value of the object in one stage. Compared with the two-stage object detection algorithm, the Region Proposal stage is not required, and the overall process is simpler. As shown in the figure above, the input image is output through the backbone and neck of the networks, and the corresponding detection frame can be generated by decoding (post-processing) in dense prediction, whereas the two-staged object detection has one more step sparse prediction to process.
Model Architecture For our study, we choose to use a One-Stage object detection model to conduct the experiements.
CSPDarknet53-tiny
Darknet53 was first proposed by YOLOv4. Its main goal is to use as a Feature Extractor to embed images into vectors to perform post-prediction regression calculations after decoding. Therefore, as the backbone feature extractor, its role is to encode the image into smaller sized feature maps which contain the unique information about the input image.
CSP
The CSP in CSPdarknet represents CSPNet architecture, which stands for Cross Stage Partial Network [1], its main purpose is to enable the architecture to achieve richer gradient combination information while reducing the amount of calculation. This goal can be achieved by dividing the feature map of the base layer into two parts and then merging them through the proposed cross-stage hierarchical structure. See CSPBlock structure in Figure 1, as the module adopting CSP architecture as part of the CSPDarknet53-tiny, it is composed of partial dense layer and partial convolutional layer. It is similar to the proposed CSPDenseNet which keeps the benefits of DenseNet’s feature for reusing characteristics, but meanwhile prevents an additional amount of duplicate gradient information by truncating the gradient flow [1]. In CSPDarknet53-tiny, the CSPBlock module divides the feature map into two parts, and combines the two parts by cross stage residual edge. This makes the gradient flow can propagate in two different network paths to increase the correlation difference of gradient information [2].
FPN Through the FPN algorithm, the high-layer features of low-resolution and high-semantic information and the low-layer features of high-resolution and low-semantic information are connected from the top to the bottom side, so that to make the semantic information from features at all scales rich. Prediction on feature layers of different scales makes the effect of generating proposals better than the YOLOv2 Darknet19 backbone network and other traditional feature extraction algorithms such as VGG16 that only predict at the top level. As Figure 1 shows, using FPN can effectively reduce detection time [2],it employs two-scale predictions (shape size in 26x26 and 13x13), conducting convolution layer and up-sampling layer at last feature layer in shapes of 26x26 and 13x13 so that to perform feature fusion.
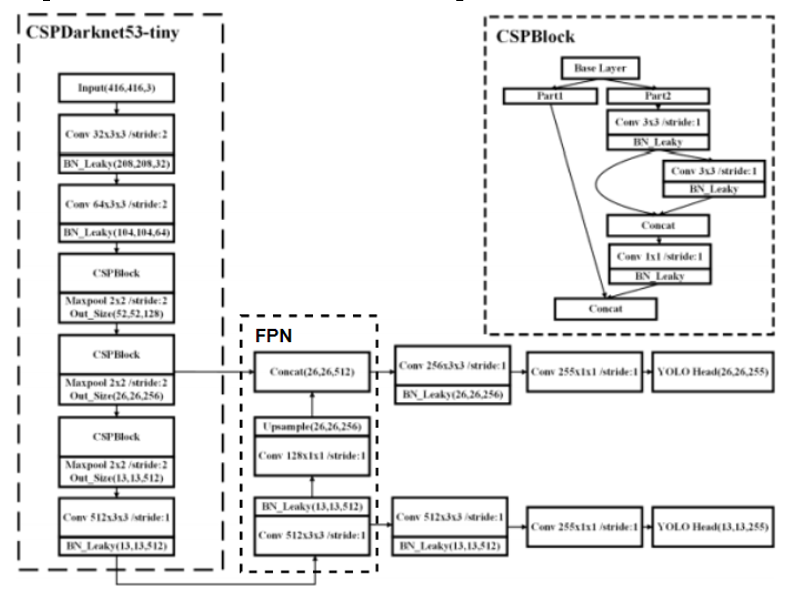
Through the above modules, the input image is extracted from the backbone feature network through the backbone feature network, and the two branch layer features are extracted through the CSP structure. After feature fusion is performed through the FPN algorithm, the two encoded image features have been obtained. The next part is to perform decoding process on these feature maps and run YOLO algorithm to make predictions. These processes are implemented by the YOLO Head in the last part of the result.
YOLO Head The shape of the feature maps output from the above feature detectors is either (26, 26, 255) or (13, 13, 255). Since YOLO, it has a grid system that divides the image into smaller cells, therefore the first two coordinates represent the number of cells in total. The last coordinate represents the encoded information about the images. The details of how encoding works would be illustrated in the next part.
Copyright @ 2021 Zizhun Guo. All Rights Reserved.