文本挖掘:机器学习建模 NLP Text Mining (7/8) - ML Models part1 (Scikit-Learn)
Author: Zizhun Guo
作者:
写于:
ML Models
Python Files
- tuning_ML_models.py: This files contains the python code to tune the ML models.
1. Perceptron Model
-
1.1. Purpose
- Tune the model by iterating values of two hyperparameters to compare results and analyze how it works with the aids of mathematical formulas
- Understand L1/L2 norm and how it affects the loss function
- Revise gradient descent and learn perceptron with back-propagation
-
1.2. Hyperparameters
- Stepping Criteria: tol
- Regularization Constant: alpha
-
1.3. Principle:
- Stopping Criteria ‘tol’
The perceptron learning model adopts SGD to fit itself. The way to compute the gradients is through back-propagation. It implements the chain rule to update the weights of the perceptron model, as it is the same for many other neural network structures. Stopping criteria as one essential hyper-parameter of the model control when to stop for the training process. Together with max_iteration times (which defines the ending condition), it somehow affects the model performance.
$Loss = Error(y, y’)$ (1)
$Loss > previousLoss - tol$ (2)
$y’ - y > y’’ - y - tol$ (3)
(1) and (2) are the definition of Loss function and how it is implemented for the stopping criteria. From (1) and (2), we get (3) that once the difference between two loss gets less than ‘tol’, in other words, the changing rate of loss becomes acceptable, the training process would stop as the model is considered convergent.
- Alpha
Alpha is a regularization rate that determines how much the l1/l2 norm(in our case) affects the loss function. If it is high, the greater proportion the regularization takes, so loss functions tend to prone to smaller weights, therefore as it gets convergent, the model is less overfitted, since the smaller weights decide less change once the predict on samples.
$L_1 = L + \alpha |W|$ (4) $L_2 = L + \alpha W^2$ (5) $W’ = W - \alpha \Delta (6)$
(4) and (5) are the formula that describe the Loss function aided by the regularization. (6) shows that each iteration of the gradient decent, the weights decreases more. Therefore as the model converges, the weights are smaller than what the regularization is not included.
- Stopping Criteria ‘tol’
The perceptron learning model adopts SGD to fit itself. The way to compute the gradients is through back-propagation. It implements the chain rule to update the weights of the perceptron model, as it is the same for many other neural network structures. Stopping criteria as one essential hyper-parameter of the model control when to stop for the training process. Together with max_iteration times (which defines the ending condition), it somehow affects the model performance.
-
1.4. Results and Analysis
- ‘tol’
- When the ‘tol’ is in the range between $1/10^1$ to $1/10^2$, the f1 is irregularly chaotic, this may own to the high ‘tol’ value that terminates the iteration process sooner than it is supposed to be converged.
- In contrast, once ‘tol’ gets smaller enough (in the range between $1/10^3$ to $1/10^4$), the f1 socre is more stable.
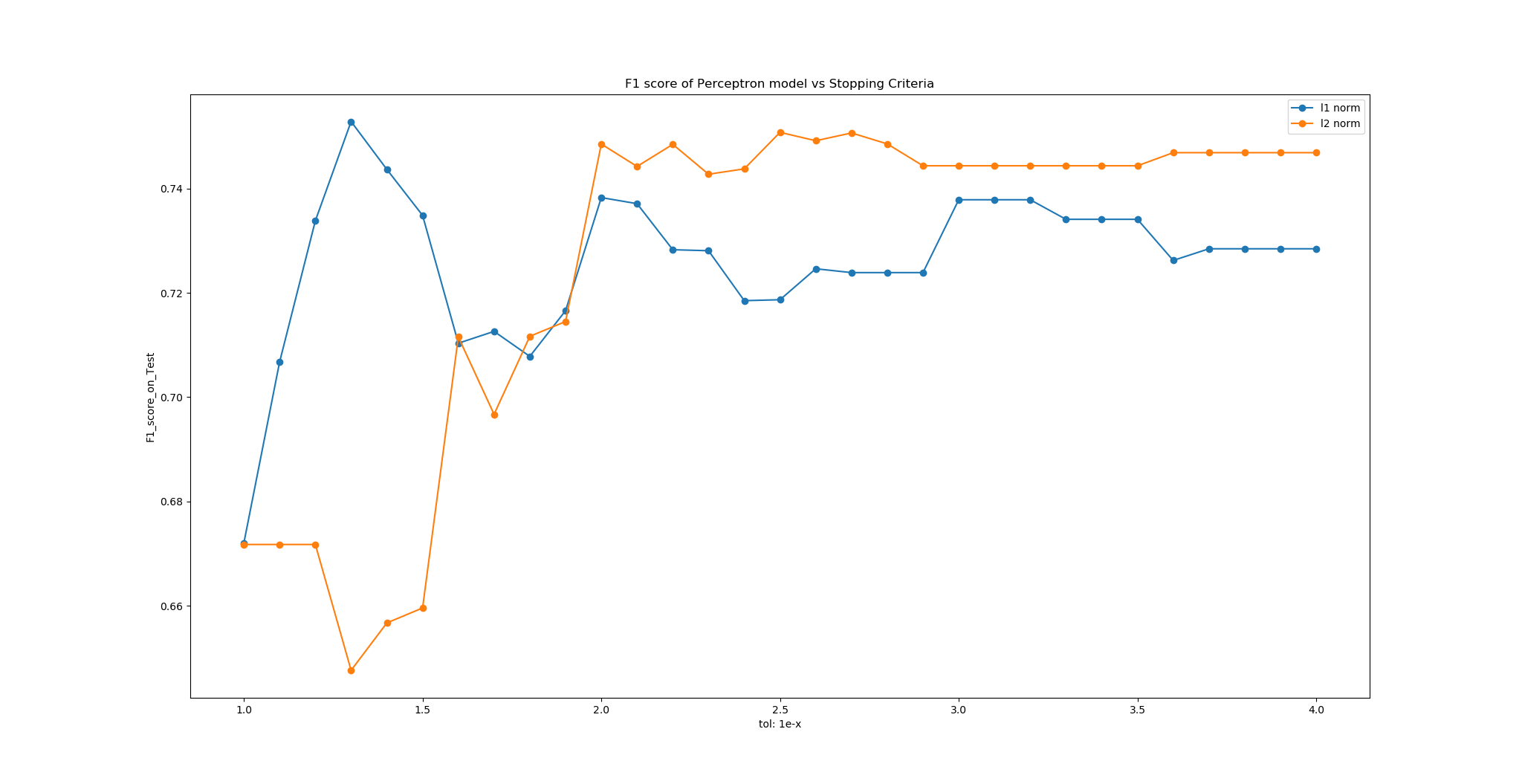
Figure 1: F1 score of Perceptron model vs Stopping Criteria - ‘alpha’
- Overall trend: f1 scores increases in sigmoid-like shape, of which the alpha value is high (left-hand side) and small on the right-hand side.
- When the alpha value is high, the regularization affects more in loss function, the optimal weights produced from training serves lower performance due to the penalty from the regularization.
- When the alpha value is low, the model tends to be overfitted since the weights of the perceptron model get greater.
- Comparing L1 norm and L2 norm, once the perceptron model arrives convergence (alpha equals around $1/10^3$), the L2 model is slightly less performed than L1 model. This can be seen as a result of the compromise that with the same alpha value assigned, L2 norm prone to produce lower weights(weight decay) hence sacrifice some precision and recall.
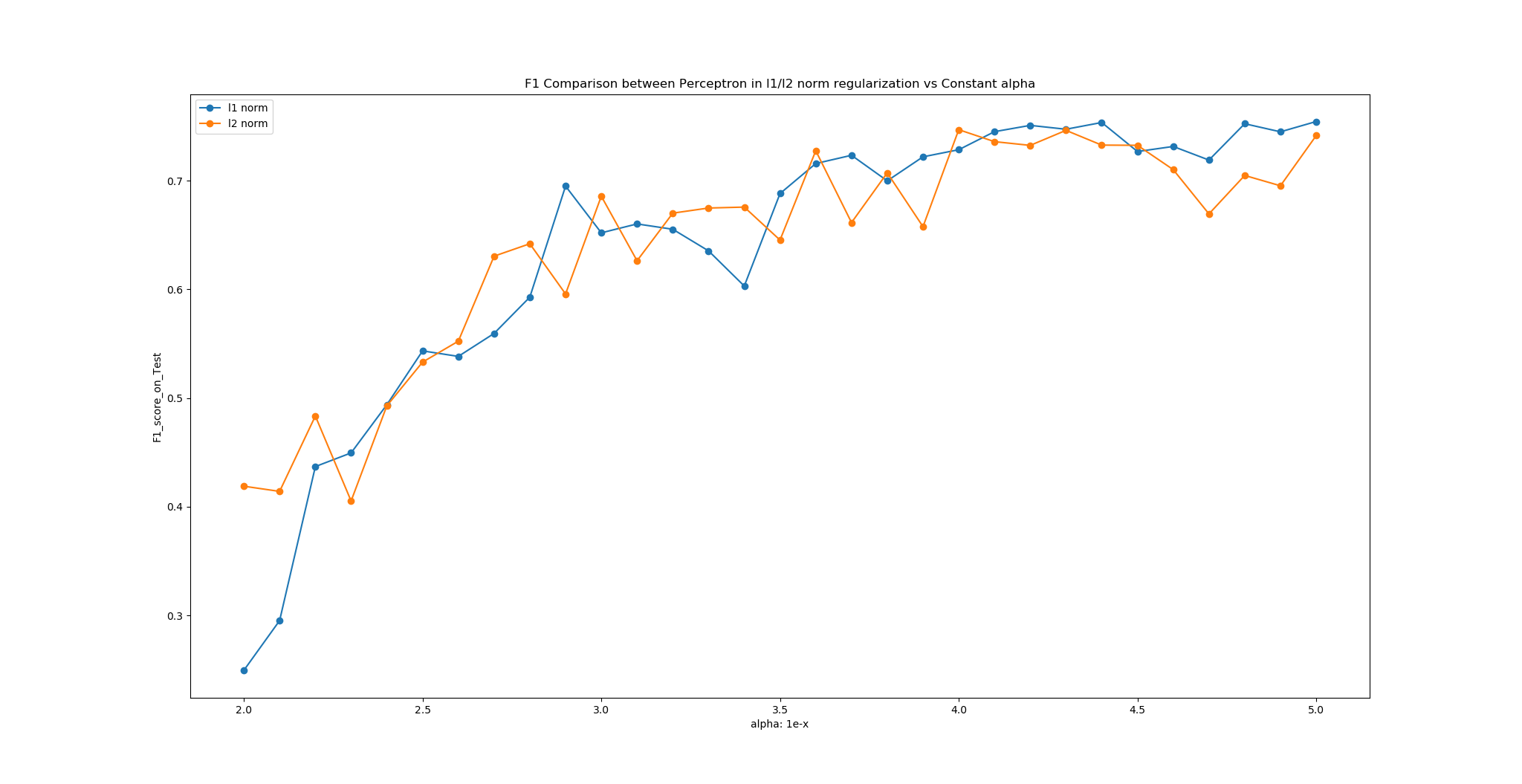
- ‘tol’
2. Other ML models: LR/SVM
Please check out textual models README.md