文本挖掘:数据集 NLP Text Mining (2/8) - Yelp Dataset
Author: Zizhun Guo
作者:
写于:
Dataset
The dataset that we used was downloaded from Yelp. The original dataset has been firstly used for Yelp Dataset Challenge and is kept updating throughout the years. It contains information about reviews, business, users, and business check-ins. The main two datasets we use is business and reviews. We specially focus on 6000 businesses evenly divided in 3 categories with their whole reviews concatenating together that the documents being features. The vocabulary size is around 180,000 which makes our documents source complex and rich in information enough to represent each business. The type of business we select is the restaurant specifically are marked in Sushi Bars, American New, and Fast Food. We believe it is firstly rich in information of the reviews due the Yelp Dataset are mainly focus on Restaurant service collection, and these three categories are not exactly similar whether in the business model or food service it provides.
For each document, we only use 6000 characters (white space inclusive) for training due to the memory limitation while conduct deep learning training hence maintains the same dataset to use for the fair models’ comparison. We conduct 10-fold cross-validation, and we assume each review for each restaurant extracted from JSON dataset file is randomly ordered, but we have ranked the restaurant based on the number of reviews they have so that when conduct concatenation, it guarantees the most reviewed restaurants to be selected as the source restaurants.
Python Files
This directory contains the actual dataset used for the experiments.
- IS_new.csv contains 4 columns(business_id, text, category, hours) of 6000 balanced records (samples)
- IS.csv contains 4 columns(business_id, text, category, hours) of 6000 balanced records (samples). The difference is the reviews in text feature is stemmed, whereas in IS_new.csv the reviews are lematized
- PS: the original dataset can be download from Yelp Dataset
1. Dataset Statistics
We use Yelp Dataset Business(Business) and Yelp Dataset Reviews(Reviews) to get training and testing samples. The main dataset to use is Reviews. The Business is helpful for tables joining to ensure the data balancing nature. Therefore, each sample attaches one review text. The samples from Reviews nevertheless need to be sampled from unique Business as the goal is to predict the category of the restaurants, so including more restaurants would be reasonable. Link: Yelp Dataset Schema
1.1 Select balanced data
Plotting histogram on both Business and Reviews help to identify the numbers of restaurants distribution.
 As the Business Histogram image shows, if we include unique restaurants to filter the Reviews, at most we can select 2363 restaurants for each of three categories(‘Fast Food’, ‘American (New)’, ‘Sushi Bars’) since we want the samples to be balanced. The histogram also shows there exist restaurants that have both categories marked, but these samples’ number is too small to consider.
As the Business Histogram image shows, if we include unique restaurants to filter the Reviews, at most we can select 2363 restaurants for each of three categories(‘Fast Food’, ‘American (New)’, ‘Sushi Bars’) since we want the samples to be balanced. The histogram also shows there exist restaurants that have both categories marked, but these samples’ number is too small to consider.
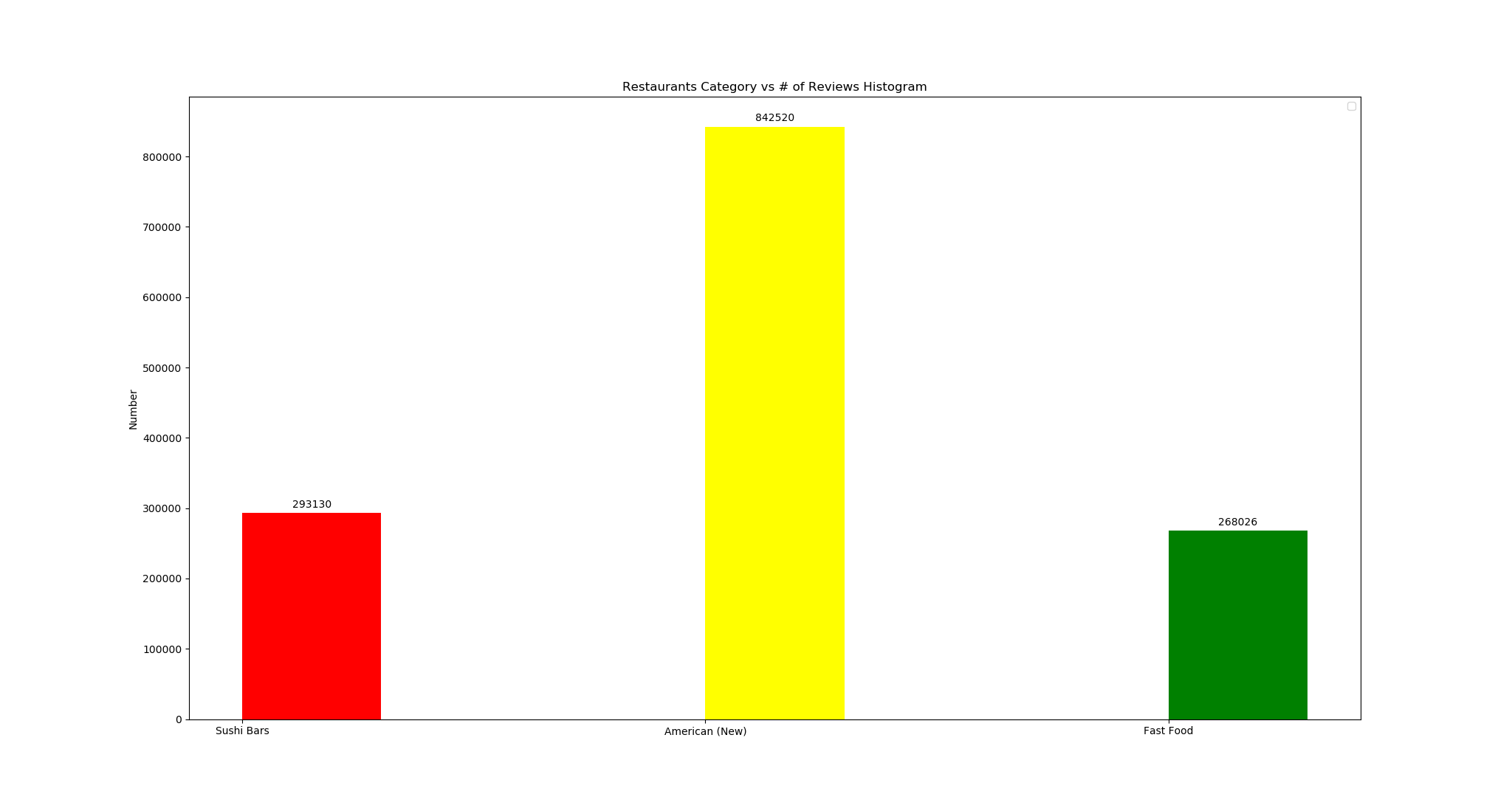 We can also observe from the Reviews histogram image, the number of samples is much overwhelmed than the Business (one restaurant can have multiple reviews), so if we do not limit our restaurant’s uniqueness condition, we could have samples as large as 268026. In our case, we include 2000 unique restaurants from each category to pre-process, of which the scalability is easy to handle. (In total 6000 samples)
We can also observe from the Reviews histogram image, the number of samples is much overwhelmed than the Business (one restaurant can have multiple reviews), so if we do not limit our restaurant’s uniqueness condition, we could have samples as large as 268026. In our case, we include 2000 unique restaurants from each category to pre-process, of which the scalability is easy to handle. (In total 6000 samples)
2. Sampling steps
- Select restaurants from only categories of ‘American (New)’, ‘Sushi Bars’ and ‘Fast Food’
- Based on their reviews number, rank the restaurants in descending order (Group by and aggregation, Join two tables)
- Select top 2000 restaurants for each category of restaurant as samples
- Apply preprocessing on the samples. Samples Update Conclusion (how it affects the experiment results): • Ranking proves to be a good way to ensure the utilized restaurants containing more information than just do randomly selection. Comparing to the dataset used from previous experiments, the median number of reviews counts for each restaurant to concatenate is between 100 to 200, the maximum reviews counts is 6000, the minimal is 3. This suggests the length for each review are at least hundreds of times over the previous method. This would yield a huge change on the final results. • With reviews scales enlarged, the sequence length increased. Unfortunately, because of the limitation on RAM size, for 10 GB available RAM can managed at least 12,800 tokens per sequence. However, the time spent on training would be linearly grew according to the tests, for a Nvidia GTX 1060 6GB video card with computing ability of 6.1, the training duration would be up to 15 hours for tuning Filter Region Size experiment. The benefits given a tiny improve less than 1 percent on validation accuracy. Therefore, for saving more time to conduct more tuning experiments, using 1000 tokens for padding the sequence length (where most reviews fully taken over the entire sequence without any zeros to pad the margin hence sequence matrix are dense) would expect to have decent output results.
3. Samples
hours text category
0 {'Tuesday': '11:0-22:0', 'Wednesday': '11:0-22... I love Deagan's. I do. I... American (New)
1 {'Monday': '9:0-0:0', 'Tuesday': '9:0-0:0', 'W... Oh happy day, finally ha... Fast Food
2 {'Monday': '10:30-21:0', 'Tuesday': '10:30-21:... This is definitely my fa... Fast Food
3 {'Tuesday': '10:0-17:0', 'Wednesday': '10:0-17... I have been here twice. ... American (New)
4 {'Monday': '11:0-21:0', 'Tuesday': '11:0-21:0'... Everything that my husba... Fast Food
5 {'Monday': '11:0-20:0', 'Tuesday': '11:0-21:0'... My husband and I go ther... American (New)
6 {'Monday': '17:0-23:0', 'Tuesday': '17:0-23:0'... As the previous person p... American (New)
7 {'Monday': '0:0-0:0', 'Tuesday': '17:0-22:0', ... This was our choice, by ... Sushi Bars
8 {'Monday': '7:0-22:0', 'Tuesday': '7:0-22:0', ... The employees are so fri... Fast Food
9 {'Monday': '6:0-6:0', 'Tuesday': '6:0-6:0', 'W... This actually used to be... Sushi Bars
RangeIndex: 6000 entries, 0 to 5999
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 hours 6000 non-null object
1 text 6000 non-null object
2 category 6000 non-null object
dtypes: float64(1), object(3)
4. Labels
As the original labels are categorical labels: Sushi Bars, American New, and Fast Food. It has to transform the categorical labels into numerical labels for the models to learn. We have transformed two types of labels (multiclass vs multilabel) for our learning models to output.
| Category before re-label | ‘Fast Food’ | ‘American (New)’ | ‘Sushi Bars’ |
|---|---|---|---|
| Category after re-label | 1 | 0 | -1 |
| index | category | Multiclass | Multilabel(One-hot Encoded) |
|---|---|---|---|
| 0 | Sushi Bars | -1 | 1 0 0 |
| 1 | Fast Food | 1 | 0 0 1 |
| 2 | Fast Food | 1 | 0 0 1 |
| 3 | American (New) | 0 | 0 1 0 |
| 4 | Fast Food | 1 | 0 0 1 |